Flagship project · open source
litertlm-kmp + NativeLM
A Kotlin Multiplatform engine for running Gemma-class LLMs fully on-device, and NativeLM — a private local-AI chat app built on top of it to prove the whole stack works end-to-end. Offline. No account. No telemetry.

What it is
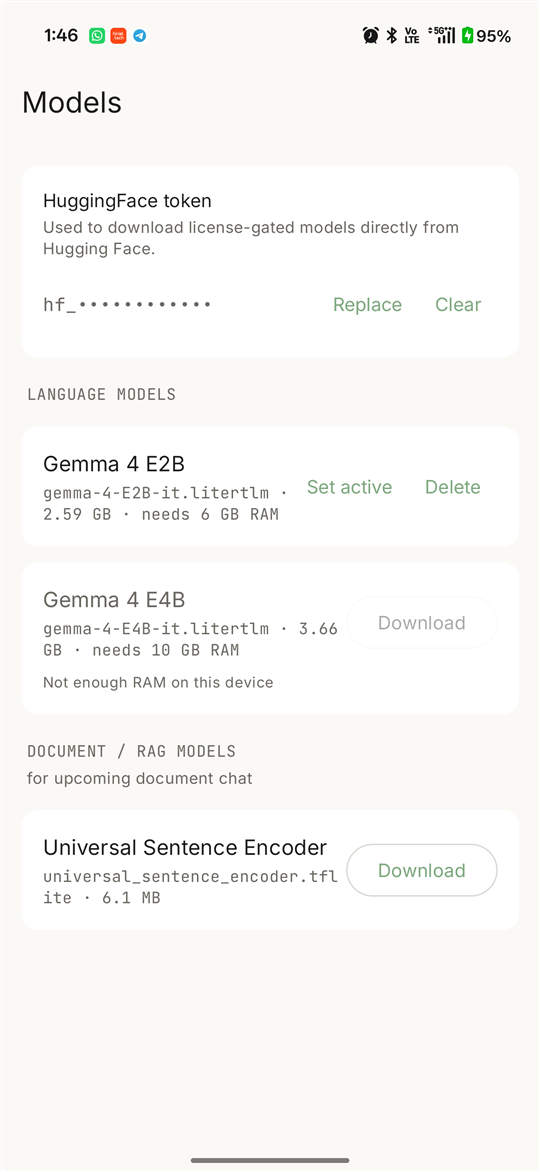
Shipping a production on-device LLM is much harder than the samples make it look: a clean abstraction over the native SDK, resumable multi-GB model downloads with integrity checks, hardware-tier gating, OEM-RAM quirks, and a function-calling layer — all shaped to run identically across platforms. The engine solves that once; NativeLM consumes it like any real app would.
v0.3 — the engineering
- Stateful KV-cache sessions. One live conversation per chat, so multi-turn memory is lossless and free — prefill is paid per new message, not re-paid for the whole history. Time-to-first-token stays flat as the chat grows.
- Backend chosen from on-device data. CPU / GPU / NPU were benchmarked on a real device; GPU/NPU can't load the community Gemma bundles, so the engine runs
CPU(6)— measured, not assumed. - Real native cancellation, conversation history, model-generated titles, and a signed, R8-minified release build (the engine ships its own consumer ProGuard rules).
val session = engine.openChatSession(history = priorTurns)
session.sendTurn(request).collect { state -> /* stream */ }
session.cancel() // real native interrupt
session.close()Backends, measured on-device
| Backend | Result |
|---|---|
| CPU (XNNPACK) | works · ~20 tok/s decode |
| GPU | can't compile the community bundle |
| NPU | bundle ships no NPU artifact |
→ CPU is the only viable backend for these bundles; CPU(6) won the thread sweep.